Navigating the Shift from Software to AI Engineering

For decades, software engineering was built on one core assumption: systems behave deterministically. Given the same input, the same code produces the same output. But the world that software operates on has changed.
Today, roughly 80–90% of global data is unstructured—PDFs, emails, chat transcripts, audio recordings, screenshots, and documents. Traditional software systems were never designed to interpret this kind of messy information. They can store it, move it, and index it, but understanding it has always required humans.
That gap is exactly where AI engineering is emerging. And the shift is deeper than just adding a model to your stack. It fundamentally changes how systems are designed.

1. The Core Conflict: Deterministic vs. Probabilistic
Traditional software is deterministic. You write rules, define logic, and the system behaves predictably. That’s why classic software excels at bounded tasks. If you ask a program to count to 100,000, it will do it in milliseconds with perfect reliability.
Large language models operate very differently. An LLM predicts the most statistically likely next token based on patterns learned during training. That means responses are probabilistic rather than deterministic. This introduces a new engineering challenge: non-determinism.
You might ask a model to return structured JSON. Sometimes it will. Other times it may return a paragraph, partially formatted text, or something that is technically correct but unusable in production. If your system depends on pleading with the model, it isn’t really under control.
The industry is increasingly moving toward function calling and structured outputs. Instead of persuading the model, you define a schema it must follow. This represents a subtle but important shift—from prompt wording to interface design.
2. The Architectural Shift: Intelligence Moving Upstream
Traditionally, data systems pushed intelligence to the far right of the pipeline. Raw data came in, ETL jobs processed it, warehouses stored it, and only later did analysts or ML teams extract insight.
LLMs are changing that by making it possible to push interpretation closer to ingestion.
This is what some people describe as a shift left.Instead of waiting until the end of a pipeline to analyze messy data, we can place models much earlier in the flow. A support transcript, audio call, uploaded document, or raw note can be interpreted at the point of entry. The system can immediately classify it, extract structured entities, tag sentiment, identify risk, or convert it into machine-readable JSON.
3. Temperature Is Not a Parameter. It’s a Product Decision.
One of the most important knobs in AI systems is temperature. Temperature controls how much randomness the model introduces when generating outputs. On paper, it looks like a simple configuration parameter. In reality, it directly shapes the user experience.
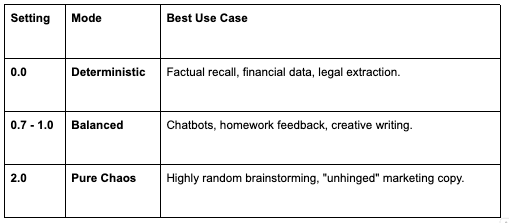
Highly random brainstorming, “unhinged” marketing copy.
4. Prompting Is Not Chatting. It’s System Design.
One of the biggest mistakes teams make is treating prompts like casual chat messages. In production systems, prompts behave more like interfaces. A few techniques have emerged as reliable patterns:
Few-shot prompting: Instead of only giving instructions, show the model examples of correct outputs. Concrete demonstrations anchor behavior far more effectively than abstract descriptions.
Step-by-step reasoning: Encouraging models to reason through tasks in stages can reduce the chance that they jump to a plausible but incorrect answer.
Instruction sandwiching” When prompts become long, models sometimes lose sensitivity to instructions that appeared earlier in the context. Repeating the key instruction at both the beginning and the end can improve reliability.
The larger lesson is simple: prompts are not casual messages. They are part of the system architecture.
5. Real AI Engineering Requires Evaluation
Prompt tweaking alone is not AI engineering. Real AI engineering begins when you introduce evaluation. That starts with defining a ground truth dataset: a collection of representative inputs paired with ideal outputs. Without that, it is impossible to know whether a prompt change actually improves the system or just looks better in one example.
From there, teams rely on different evaluation metrics depending on the task.
Then measure against it using semantic metrics:
ROUGE — for exact word overlap, useful in legal and financial contexts
Cosine Distance / BERTScore — for measuring whether the meaning is preserved, even when the words differ (”sprint” vs. “run,” for example)
From there, tools like Autoflow can programmatically test hundreds of prompt variations against your metrics and identify the mathematically superior version. That’s the difference between tuning by feel and optimizing by evidence.